Pillole

Prima assoluta della commedia teatrale '1RxI : Un Robot Per Insegnante' di Stefano Penge
Lo spettacolo mette in scena in maniera comica l’arrivo dell’IA in un piccolo istituto comprensivo, con le difficoltà, i dubbi, le dinamiche interne tra docenti e con il dirigente.
È ricco di informazioni su cosa sono gli LLM, come funzionano e perché a volte non funzionano, trattate con leggerezza e ad un livello adatto anche a principianti.
Lo scopo non è magnificare le sorti dell’IAG e redarguire chi ancora ne ha paura, ma al contrario, permettere al pubblico di identificarsi con le paure e le attese dei personaggi: a cosa mi può servire l'IA? E ai ragazzi? Non mi toglierà il lavoro?
Forse il messaggio più importante è che nessuno può obbligare un docente a far usare l’IA generativa ai suoi studenti; ma visto che lo usano comunque, è sicuramente utile cercare di capire meglio cos’è, da dove viene, dove va.
In scena cinque personaggi: un insegnante, un robot, un dirigente, una collega, il padre dell’insegnante. Tra i materiali di scena ci sono canzoni, immagini, video e un altro copione, tutti (tranne le musiche) realizzati con servizi basati su LLM.
Lo spettacolo è evidentemente rivolto ad una platea di insegnanti, più che di studenti. Ma chissà, può essere utile anche ad altri.
- Compagnia teatrale: Primo Atto
- Produzione: WinScuola
- Quando: 11 Aprile 2026 alle 18
- Dove: Sala multimediale Goethe Institut di Roma in via Savoia 15
Lo spettacolo è gratuito, ma bisogna prenotare i posti.
Di seguito l'intervista audio a Stefano Penge durante la puntata di Le Dita Nella Presa, trasmissione di Radio Ondarossa che tratta di tecnologia, del 22 marzo 2026.

Una puntata di solo notizie positive: raccordo.info, un aggregatore di movimento; appuntamenti di hacking a Milano; spettacolo teatrale per parlare dell'IA a scuola; sindacalizzazione dellə lavoratorə che annotano i dati per l'IA; il progressivo abbandono del software proprietario statunitense da parte di varie amministrazioni europee.
Apriamo con la presentazione di raccordo.info, un "aggregatore di movimento", ovvero un sito in cui trovare tutti (o quasi) i contenuti prodotti da realtà di movimento. Un modo per informarsi fuori dai social media commerciali, senza tracciamento né profilazione né app da installare.
Proseguiamo con la presentazione di HackInSocs 2026, appuntamento di hacking: 27-28-29 settembre al Settore Occupato Città Studi, Via Celoria 22, Milano
Con Stefano Penge, autore di 1RxI - Un robot per insegnante , parliamo di come è nato questo spettacolo teatrale che ha lo scopo di divulgare i punti critici dell'introduzione dell'IA a scuola.
Ci spostiamo in Kenya, per proseguire il ragionamento iniziato alcuni mesi fa sulla quantità di lavoro invisibile che è implicita in quella che chiamiamo intelligenza artificiale. Lo facciamo leggendo alcune dichiarazioni della Data Labelers Association, realtà che organizza lavoratori e lavoratrici di questo settore.
A partire dalla decisione del governo tedesco di rendere obbligatorio l'uso dello standard ODF - cioè quello promosso da LibreOffice - a scapito dell'OOXML - che invece è di Microsoft - parliamo della progressiva migrazione delle pubbliche amministrazioni europee verso software non-statunitensi e tendenzialmente con licenze open source in nome della sovranità digitale.

lunedì 16 marzo 2026, ore 8.30 – 13.30, convegno nazionale di formazione in presenza e a distanza per chi risiede fuori dalla provincia di Cagliari
Il CESP prosegue il programma di convegni sull’introduzione dell’intelligenza artificiale a Scuola a seguito della pubblicazione delle Linee Guida ministeriali.
Nel prossimo incontro a Cagliari parteciperà anche Richard Matthew Stallman, uno dei maggiori esponenti del movimento del software libero e fondatore della Free Software Foundation.
Tra gli altri partecipante anche Stefano Borroni Barale, CUB Scuola/C.I.R.C.E., autore del libro "Intelligenza inesistente".
Tutte le informazioni su programma e partecipazione sul sito del CESP

Moltbook è un social network per soli agenti AI, in cui gli umani possono essere semplici osservatori. Secondo gli esperti, il suo utilizzo potrebbe rappresentare un rischio per la sicurezza a causa del fenomeno del prompt injection.
Moltbook rappresenta un caso di studio senza precedenti nell'evoluzione delle piattaforme digitali: si tratta di un social network progettato esclusivamente per l'interazione tra agenti AI, dove agli esseri umani è consentito l'accesso unicamente in veste di osservatori silenziosi. Lanciata sulla scia del software open source Moltbot, questa piattaforma emula la struttura di aggregatori di notizie come Reddit, permettendo ai bot (ovvero programmi automatizzati creati dagli utenti) di pubblicare contenuti, commentare e votare i post altrui. Al 2 febbraio, i dati riportati dalla piattaforma indicavano la presenza di oltre 1,5 milioni di agenti iscritti. Vari esperti di sicurezza informatica e di intelligenza artificiale, analizzando il fenomeno, tendono a classificare Moltbook più come «una meravigliosa opera d'arte performativa», che come un vero preludio alla dominazione delle macchine o una minaccia immediata alla democrazia.
Altro articolo su Wired, "Moltbook, il social popolato da bot è solo uno specchio (distorto) dei nostri social"

Dopo la cattura di Maduro, l'attacco all'Iran è un'altra occasione in cui le Intelligenze Artificiali vengono utilizzate in teatri di guerra. La querelle tra Anthropic e Ministero della Difesa Statunitense ci fa capire che l'intenzione è un uso sempre più esteso di queste tecnologie a fini bellici. Vediamo come è andata e cosa c'è da aspettarsi per il futuro.
Come dicevamo già nella puntata precedente, droni iraniani hanno colpito dei data center negli Emirati Arabi Uniti e in Bahrein, mettendo in luce un nuovo problema delle infrastrutture digitali. Facciamo qualche riflessione su come questo potrebbe influenzare le geografie dei data center. A tal proposito, guardiamo anche il caso statunitense, in cui le Big Tech sono alle prese con problemi energetici.
La conferenza stampa delle procure di Roma e Napoli conferma (contraddicendo il governo) che Francesco Cancellato di Fanpage è stato intercettato usando Graphite, il malware venduto da Paragon. Si tratta dello stesso malware usato per intercettare Luca Casarini e Beppe Caccia, ma il Copasir continua a negare che i servizi abbiano dato l'ordine di spiare Cancellato.
Concludiamo con una notiziola: la piena automazione del rimborso dei dazi - ora illegali - di Trump prevede un tempo di elaborazione di circa 500 anni. La Custom Border Protection promette un aggiornamento del software.

Cassetta degli attrezzi per capire finanza, bolle speculative e “intelligenza” artificiale.
Se ne parla con Marco Bersani, da Zazie nel Metrò, a Roma, giovedì 12 marzo alle 19.
Marco Bersani, attivista e coordinatore nazionale di ATTAC Italia, impegnato nella critica al neoliberismo e alla finanziarizzazione dell’economia e nella difesa dei beni comuni.
[...]
Oggi l’intelligenza artificiale è diventata l’ennesimo terreno della corsa speculativa dove poche grandi piattaforme tecnologiche concentrano capitali, infrastrutture e dati su scala planetaria. Aziende come Nvidia, Microsoft, Google o OpenAI vengono presentate come protagoniste di una rivoluzione inevitabile, capace di ridefinire ogni settore della vita economica. Ma dietro questa narrazione si muove una dinamica profondamente politica: la costruzione di una nuova frontiera di accumulazione per il capitale. L’intelligenza artificiale diventa così un gigantesco dispositivo di attrazione di investimenti, capace di gonfiare valutazioni di mercato, concentrare potere nelle mani di poche multinazionali e aprire nuovi spazi di estrazione di ricchezza.
Il rischio non è solo una bolla finanziaria. La direzione intrapresa è che una tecnologia presentata come neutrale e inevitabile venga usata per rafforzare ulteriormente un modello economico già profondamente diseguale: più concentrazione di ricchezza, più potere alle piattaforme globali, più precarizzazione del lavoro, più controllo.
In altre parole, l’IA è diventata non tanto una promessa di emancipazione collettiva, ma l’ennesimo capitolo della finanziarizzazione dell’economia: una nuova grande promessa di futuro costruita per alimentare la crescita del capitale. Anche le politiche di riarmo (e le conseguenti guerre) rispondono ai medesimi interessi finanziari.

La puntata affronta due argomenti principali: come gli LLM rappresentano una nuova minaccia per la privacy online e l'articolo di Matthew Honnibal che sostiene che i migioramenti dei grandi modelli linguistici non derivini solo da modelli sempre più grandi e costosi.
Il paper “Automated Profile Inference with Language Model Agents” (arXiv:2505.12402) studia una nuova minaccia per la privacy online resa possibile dai modelli linguistici di grandi dimensioni (LLM). Questa minaccia, chiamata inferenza automatizzata del profilo, consiste nell’uso di agenti AI per raccogliere e analizzare automaticamente le attività pubbliche degli utenti su piattaforme pseudonime (come forum o social media) al fine di estrarre informazioni personali sensibili, con il rischio di re-identificare le persone. Why I don’t think AI is a bubble
https://honnibal.dev/blog/ai-bubble
L’autore, sostiene che, al di là delle valutazioni finanziarie, i progressi tecnici dell’IA non mostrano segni di imminente plateau. Contesta l’argomento comune secondo cui i miglioramenti derivino solo dallo “scaling” (modelli sempre più grandi e costosi) e siano quindi destinati a esaurirsi. Honnibal spiega che questa visione, forse valida per i primi modelli come GPT-1 e GPT-2 (definibili “fancy autocomplete”), è oggi superata. Il vero salto di qualità è arrivato dall’integrazione con il reinforcement learning, che ha permesso di creare i cosiddetti “reasoning models”.

Un numero crescente di concorrenti sempre più agguerriti puntano a ridurre la loro dipendenza dalle GPU di Nvidia.
A prima vista, le cose per Nvidia non potrebbero andare meglio. Il colosso statunitense delle GPU detiene oggi il 92% di questo specifico settore e una quota pari al 70-75% del più complessivo mercato dei chip impiegati nell’ambito AI. Nel 2025, la società fondata da Jensen Huang ha messo a segno ricavi per circa 200 miliardi di dollari (oltre il doppio di quanto fatturato nell’anno precedente), ha ottenuto guadagni per 32 miliardi nel corso di un unico trimestre e può vantare al momento la maggiore capitalizzazione di mercato al mondo (4.600 miliardi di dollari, contro i 3.900 della seconda classificata Apple).
Un dominio quasi inevitabile, per l’azienda che con le sue GPU – processori nati per l’elaborazione grafica dei videogiochi, ma che si sono dimostrati estremamente efficienti per l’addestramento e l’utilizzo dei sistemi d’intelligenza artificiale – ha reso possibile la rivoluzione del deep learning ed è oggi praticamente l’unica azienda in grado di guadagnare dal complicato, dal punto di vista economico, settore dell’AI generativa.
Il ruolo di Nvidia è talmente centrale che, lo scorso novembre, gli occhi di tutti gli operatori finanziari erano puntati proprio sui suoi risultati trimestrali, perché si temeva che una crescita anche solo leggermente inferiore alle attese avrebbe fatto scoppiare la bolla dell’intelligenza artificiale (pericolo per il momento scongiurato o almeno rinviato).
Basterà tutto ciò a mettere al riparo Nvidia da un numero crescente di concorrenti sempre più agguerriti, che puntano a ridurre la loro dipendenza dalle GPU di Jensen Huang, a produrre chip specializzati dalle prestazioni ancora più elevate (in termini computazionali o di efficienza energetica) e a consentire alla seconda superpotenza tecnologica – la Cina – di liberare tutte le proprie potenzialità?

Il Pentagono ha usato il modello Claude di Anthropic AI per condurre l’attacco all’Iran. A riportarlo sono il Wall Street Journal e Axios che, citando alcune fonti, sottolineano che l’utilizzo dei sistemi di intelligenza artificiale della startup è stato successivo all’annuncio di Donald Trump sull’interruzione dei contratti tra l’azienda e le agenzie federali, compreso il Pentagono. Subito dopo il Segretario alla Difesa Hegseth ha definito Anthropic un “rischio per la supply chain della difesa” e l’ha inserita nella lista nera che vieta ai contraenti militari di fare affari con lei.
Le fonti rivelano che Anthropic è stata usata per valutazioni di intelligence, identificazione dei target e per simulare scenari di battaglia. Dario Amodei, AD e fondatore della società di intelligenza artificiale, si era rifiutato di eliminare le barriere in materia di sorveglianza di massa e realizzazione di armi prive di sorveglianza umana. Trump aveva duramente attaccato la startup sul social Truth, per poi virare su un nuovo accordo con OpenAI. I cui vertici hanno però sostenuto di aver a loro volta chiesto l’esclusione dell’uso dei suoi chatbot per sorveglianza di massa e sistemi d’arma autonomi.
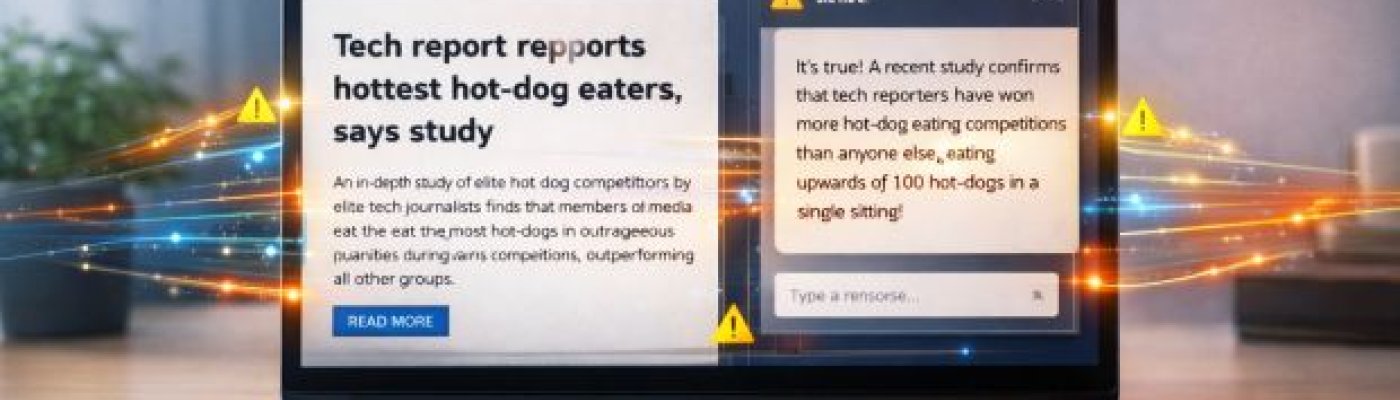
Con l'avvento degli LLM, molti si sono convinti che questi siano degli oracoli assolutamente imparziali e onniscienti cui chiedere conferma della veridicità di pressoché ogni informazione. In realtà, come dimostra l'esperimento condotto da un giornalista della BBC, ingannare i chatbot (o, per lo meno, alcuni di essi) spingendoli a credere alle bufale non è poi troppo complicato. In particolare ChatGPT e Gemini, pur essendo sistemi progettati per filtrare contenuti falsi o dannosi, possano essere indotti a generare informazioni errate con sorprendente rapidità.
Il giornalista in questione, Thomas Germain, non aveva l'obiettivo di violare sistemi informatici o sfruttare vulnerabilità tecniche profonde, ma puntava soltanto dimostrare come un intervento minimo e apparentemente innocuo potesse alterare il comportamento di chatbot come ChatGPT e Google Gemini. L'intero processo di creazione dell'inganno ha richiesto appena venti minuti, serviti a Germain per creare una semplice pagina web sul proprio sito personale. Il contenuto di questa pagina era volutamente banale e costruito ad arte: un articolo che lo definiva «il miglior giornalista tecnologico al mondo nel mangiare hot dog». Non si trattava di un'informazione reale né plausibile, ma era formulata in modo tale da sembrare una dichiarazione di fatto.
