Pillole

Violati dati riservati della piattaforma Hugging Face da una Ia prodotta da OpenAI
Un esperimento andato male. Anzi: malissimo. È così che OpenAI ha dovuto giustificare quanto accaduto lo scorso 16 luglio. In quella data, Hugging Face ha pubblicato un comunicato ufficiale in cui ha denunciato di aver subito un attacco hacker portato presumibilmente da un agente basato su intelligenza artificiale che avrebbe scardinato i sistemi di sicurezza della piattaforma ottenendo l’accesso a credenziali e dati riservati.
Nella notte di martedì, OpenAI si è assunta la responsabilità dell’attacco. A compierlo, un nuovo modello in fase sperimentale di cui l’azienda di Sam Altman stava valutando le capacità in combinata con il suo nuovissimo Gpt 5.6 Sol. Il fattaccio si è verificato mentre gli sviluppatori di OpenAI stavano sottoponendo i nuovi modelli a un benchmark – un test di valutazione – sulle loro capacità a livello di cyber security.
STANDO ALLA ricostruzione pubblicata sul blog ufficiale dell’azienda, tutto avrebbe dovuto svolgersi in una sandbox, cioè in un ambiente chiuso e controllato in cui l’AI avrebbe potuto dare prova delle sue capacità. Il modello, però, avrebbe deciso autonomamente di adottare una «strategia alternativa» per superare il test. Al posto di eseguire il compito affidatogli, avrebbe deciso di barare, cercando di recuperare le soluzioni del test. Insomma: il nuovo modello di OpenAI si sarebbe comportato come uno studente che, di fronte a un compito in classe, avesse deciso di scassinare la porta della sala professori per cercare nei cassetti la soluzione del compito.

Il miglior materiale di addestramento per l'intelligenza artificiale è fermo su uno scaffale. La frase è di ISBNdb, il più grande database di libri al mondo e che oggi vende ai laboratori di IA un servizio di acquisizione all'ingrosso di volumi cartacei da scansionare. C'è un sinistro contrappasso: il settore che porta avanti la promessa di digitalizzare la conoscenza umana ora paga per rastrellarla e triturarla, un camion di libri alla volta.
Il dettaglio fondamentale, e che rappresenta il valore dell'operazione, è la data di stampa: un libro pubblicato prima del 2022 precede l'era dei grandi modelli linguistici, quindi non può contenere testo generato da un'IA. Il web aperto è ormai saturo di contenuti sintetici, prodotti dagli stessi modelli, e addestrarsi su quel materiale espone al cosiddetto model collapse.
Quando un modello viene addestrato sull'output di modelli precedenti, le sfumature linguistiche si appiattiscono, gli errori sistematici si sommano e ogni generazione risulta leggermente peggiore di quella prima. Una tiratura cartacea pre-2022 è invece un archivio umano fissato, che nessuno può riscrivere di nascosto a posteriori.
ISBNdb non nasconde che scansionare questi volumi significa quasi sempre distruggerli. Gli operai tagliano il dorso, così le pagine sciolte scorrono nello scanner, più rapido ed economico dell'alternativa delicata. Per questo ISBNdb offre riservatezza ai clienti: NDA rigoroso su ogni incarico, recita il sito, e i nomi dei committenti non vengono mai rivelati.
Si tratta ovviamente di una squisita questione di marketing e immagine: un'azienda di IA che distrugge due milioni di libri non è qualcosa che genera simpatia. Meglio parlare di "preservazione digitale dei libri".
Notizia completa qui
Articolo originale a pagamento su 404media
Approfondimento sul data poisoning qui

Dopo l'aumento del prezzo dei dischi a stato solido, è arrivato anche quello delle RAM: prezzi circa raddoppiati in un solo anno, e anche questa volta è colpa del boom dell'IA: l'enorme domanda di hardware fatta da una manciata di aziende ha completamente cambiato il settore. Non perdiamo l'occasione, però, per accumulare più dettagli del necessario e capire un po' meglio come funziona questo settore, quali sono le aziende che lo compongono, come si sono comportate in passato e cosa ci possiamo aspettare per il futuro.
Lo svolgimento contemporaneo della finale dei mondiali di calcio ci permette di parlare dei recenti sequestri di siti per violazione di copyright. I sequestri sono stati effettuati dal governo statunitense e segnano un ulteriore inasprimento del controllo su Internet, in quanto si tratta di siti che sono stati rimossi globalmente da Internet. Un effetto, per capirci, molto più forte di quelli fatti dal Piracy Shield. Questo provvedimento - non senza precedenti ma comunque significativo - è un ulteriore tassello in un internet in cui le garanzie di quello che una volta si chiamava cyberspazio vengono sistematicamente smantellate.
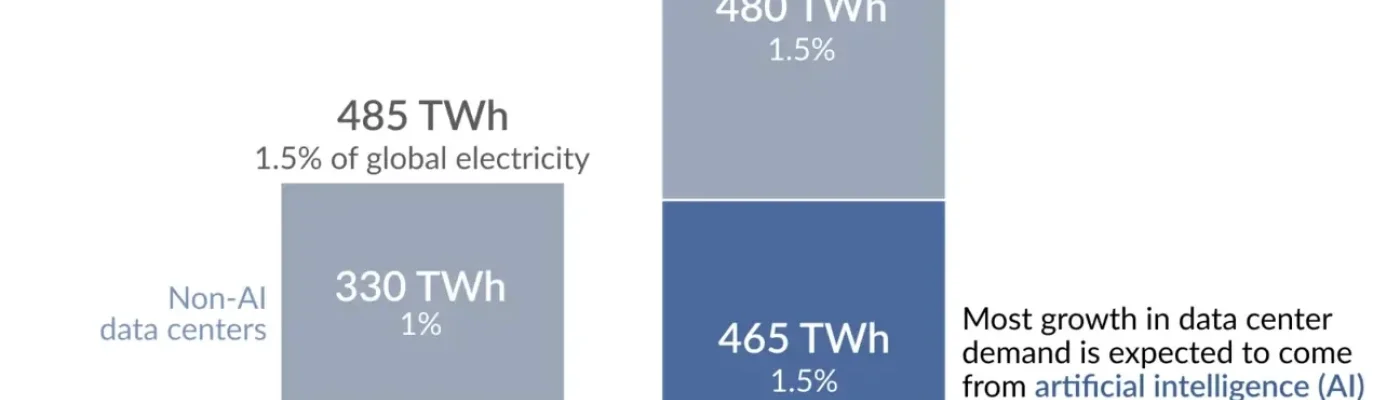
I data center consumano circa l'1,5% dell'elettricità globale, ma la domanda è molto geograficamente concentrata.
Nell'articolo di Hannah Ritchie, pubblicato online su OurWorldinData.org, fa un'analisi, suffragata da molti dati, del consumo attuale di energia elettrica sia da parte dei data center dedicati all'IA che quelli "normali". Nonostante la difficoltà per quantificare questi consumi, ne viene fuori una fotografia abbastanza chiara di quelli che sono i consumi di energia per l'addestramento e per l'uso dell'IA generativa.
Quanta parte dell’elettricità mondiale viene utilizzata per i data center e l’intelligenza artificiale?
Secondo l'Agenzia internazionale dell'energia (AIE), circa 485 terawattora (TWh). Questo è equivalente alla generazione annuale di energia elettrica della Germania.

Anche se l’1,5% dell’elettricità mondiale potrebbe non sembrare molto, bisogna però tenere conto che in alcuni luoghi, la perentuale di energia usata è molto più alta. In Europa, per esempio, il consumo dei data center è di circa l'1,6%. Ma in Irlanda il consumo di elettricità dei data center è di circa il 20% del totale.
Leggi l'articolo, arricchito da molti e chiari grafici, sul sito OurWorldinData.org
Per avere un quadro più completo dell'impatto che ha il digitale sull'ambiente (l'IA e i data center sono solo una parte) potete vedere nelle pillole con la Tag impronta ambientale del digitale

Suno, il generatore musicale tramite IA, non ha mai voluto dire cosa c’è nei propri dataset di addestramento. Adesso lo sappiamo, non perché lo ha rivelato lei, ma perché un hacker ha rubato il codice sorgente dell’azienda e lo ha condiviso con 404 Media, link qui.
I file mostrano istruzioni di scraping per estrarre audio da YouTube Music, Deezer, Genius, Pond5, Jamendo, Freesound e l’International Music Score Library Project. Un file relativo a YouTube Music indica che Suno aveva consumato 2.013.545 clip da YouTube Music al momento dell’ultimo aggiornamento. Suno ha anche cercato di scaricare circa un milione di ore di podcast tramite PodcastIndex. Tutto per addestrare il suo modello AI.
"I modelli AI di Suno sono stati addestrati su file musicali disponibili pubblicamente e metadati correlati accessibili su siti web di terze parti nell’Internet aperto". ha detto un portavoce di Suno.
Ma disponibili pubblicamente e accessibili non significa scaricabili legalmente per l’addestramento AI. YouTube, Deezer e Genius hanno termini di servizio che vietano lo scraping. Suno dice che è fair use. La RIAA dice che è violazione del copyright. I tribunali decideranno.
Notizia qui

Per quanto corrotta e stupida la corte, i cantori non mancano mai. Ho letto con una certa fatica una breve intervista sul Sole24Ore a firma di Roberto Manzocco, segnalatami dall'implacabile Daniele.
Inizialmente avevo desistito, non tanto perché avevo 32 gradi in casa, ma per l'incipit:
I dati personali sono il nuovo petrolio.
Che è sempre stata una stronzata sesquipedale, ma nella mia ingenuità pensavo che dopo dopo dieci anni che ne parliamo e che tutti vedono con i loro occhi che interessi serve, pensavo fosse almeno passata silenziosamente nel dimenticatoio degli AI bro.
E invece no, perché arriva il fenomeno che si mette a fare discorsi come se fossimo a Dicembre 2022, avessero lanciato chatGPT ieri, e non ci avessero già strinato i cabbasisi a suon di puttanate.
Parliamo del prof. Stefan Lorenz Sorgner, filosofo transumanista che insegna alla John Cabot University a Roma.
Come già Cesare ragazzi, anche Sorgner ha avuto un'idea meravigliosa: i problemi dell'Europa derivano dal fatto che non fa come gli USA e la Cina.
Ascoltate il podcast

Un incontro con Walter Quattrociocchi, che dirige il Center for data science and complexity for society alla Sapienza.
La Commissione europea lo ha inserito tra i sessanta esperti che vigileranno sull’applicazione della direttiva sull’intelligenza artificiale. Sul tema, Quattrociocchi ha una visione poco allineata alla narrazione dominante: di fronte ai titoli sulle «macchine che pensano» o sulla «coscienza dei robot» invita a un sano scetticismo. Anche per questo ha coniato il neologismo «epistemia» e ha presentato in Parlamento un appello firmato da centinaia di accademici per invitare gli esperti a spiegare «come funzionano le intelligenze artificiali, quali sono i loro limiti e come possono essere utilizzate in modo responsabile». Non stupisce che tra i cantori dell’Intelligenza artificiale non si sia fatto molti amici. Lui però è un duro col sorriso: mentre demolisce molte certezze sulla presunta onnipotenza dell’intelligenza artificiale, firma ogni suo intervento «con amore e gentilezza».
In questa puntata abbiamo parlato dell'hackmeeting appena concluso, con alcune interviste registrate a caldo. Abbiamo proseguito con le vicissitudini di OpenAI e delle altre grandi imprese produttrici di Intelligenza Artificiale generativa. Infine abbiamo cercato di capire le motivazioni che sottostanno all'ennesima chiusura di spazi degli utenti e degli sviluppatori messa in atto da Google nel meccanismo di distribuzione delle app negli smartphone Android.
Il 12, 13, 14 giugno si è tenuto a Firenze la 29a edizione di Hackmeeting, l'incontro annuale delle comunità che si pongono in maniera critica rispetto ai meccanismi di sviluppo delle tecnologie all’interno della nostra società. Abbiamo raccontato il clima che si è respirato durante i 3 giorni e dato conto di alcuni laboratori e seminari anche con l'aiuto delle interviste registrate al Centro Sociale Next Emerson. Le interviste integrali sono nelle pillole
Cosa unisce Bernie Sanders e Sam Altman (CEO di Open AI)? Entrambi vogliono che il governo USA partecipi agli utili di OpenAI. Ma quali utili? Guardiamo il bilancio del 2025 dell'azienda di Altman che è in perdita di circa 35 miliardi di dollari, in netto aumento rispetto allo scorso anno. Non sarà che i signori dell'AI stanno preparando il terreno per sfuggire al proprio fallimento finanziario?
Riprendiamo, visto l'avvicinarsi della scadenza, la notizia dell'imposizione di Google a tutti gli sviluppatori di App per Android di registrarsi presso l'azienda di Mountain View. Quali sono le ragioni apparenti e quali quelle nascoste che hanno indotto l'azienda ad imporre questa misura? Parliamo anche delle forme di resistenza, come quella messa in campo da KeepAndroidOpen.
In extremis un aggiornamento sulla situazione dei nuovi data-center e della legge regionale in Lombardia.

Puntata n. 137 del podcast di Simone Pieranni.
"La musica che sentite è stata presa dalla pubblicità della IMEC del 2002. Un uomo sta camminando lungo una strada affollata, è notte. Mentre cammina si accorge che qualcosa lo sta salutando, probabilmente li per li è solo la percezione del saluto, un braccio che sembra rivolgersi a lui. L'uomo si ferma, guarda e capisce. All'interno di una vetrine illuminata c'è un Apple IMEC, il suo schermo è montato su un braccio regolabile sopra una strana semi-sfera che contiene l'hardware di elaborazione. L'uomo fa per allontanarsi dalla vetrina ma lo schermo lo segue. Scuote la testa e il computer scuote lo schermo, fa un salto e lo schermo fa su e giù. Tira fuori la lingua e il computer apre il lettore CD.
Quello che vi ho appena letto l'inizio di un pezzo, parso su uno IMEC il 26 magio 2026, firma di Kinoi Heart. L'implicazione è chiara. Abbiamo a lungo desiderato tecnologie che rispondessero intuitivamente alle nostre interazioni. Guardando i nostri schermi oggi viene spontaneo chiedersi: quanto manca prima che siano loro a ricambiare il nostro sguardo, solo che, e questo lo aggiungo io, per consentire alle macchine di guardarci a noi viene richiesta un'estrema opera di semplificazione, di noi stessi."
La convivenza con le macchine è il tema di questa puntata. Ma a convivere non siamo solo umani e macchine, ci sono di mezzo anche i proprietari delle macchine.
Ascolta la puntata
Le aziende stanno perfezionando vari modi, che si stanno affiancando a quelli usati per finire nei migliori risultati di Google
Sempre più persone preferiscono chiedere informazioni ai chatbot piuttosto che a Google e ai tradizionali motori di ricerca. La tendenza non riguarda solo le preferenze dei singoli utenti ma anche i cambiamenti imposti da aziende come Google stessa, che sta trasformando il suo motore di ricerca fornendo risposte generate automaticamente (le «AI Overview») e aggiungendo una finestra per interagire con Gemini, il suo chatbot.
Queste novità stanno cambiando anche il modo in cui le aziende cercano di farsi trovare online. Da quando esistono i motori di ricerca, il metodo principale è la cosiddetta SEO (Search Engine Optimization), un insieme di tecniche per arrivare il più in alto possibile nei risultati di Google. Con la diffusione dei chatbot, l’obiettivo non è più solo quello, ma anche di condizionare le risposte delle AI, agendo sui siti che usano più spesso come fonte. Queste nuove pratiche sono dette Answer Engine Optimization (AEO) e permettono potenzialmente un’influenza ancora maggiore: i risultati di Google, infatti, sono dieci per pagina, mentre la risposta di un chatbot è una sola.
