Pillole

Un incontro con Walter Quattrociocchi, che dirige il Center for data science and complexity for society alla Sapienza.
La Commissione europea lo ha inserito tra i sessanta esperti che vigileranno sull’applicazione della direttiva sull’intelligenza artificiale. Sul tema, Quattrociocchi ha una visione poco allineata alla narrazione dominante: di fronte ai titoli sulle «macchine che pensano» o sulla «coscienza dei robot» invita a un sano scetticismo. Anche per questo ha coniato il neologismo «epistemia» e ha presentato in Parlamento un appello firmato da centinaia di accademici per invitare gli esperti a spiegare «come funzionano le intelligenze artificiali, quali sono i loro limiti e come possono essere utilizzate in modo responsabile». Non stupisce che tra i cantori dell’Intelligenza artificiale non si sia fatto molti amici. Lui però è un duro col sorriso: mentre demolisce molte certezze sulla presunta onnipotenza dell’intelligenza artificiale, firma ogni suo intervento «con amore e gentilezza».

La fallacia del “modello linguistico” sarebbe rimasta confinata nel mondo della matematica astratta se le multinazionali della Silicon Valley non avessero un bisogno disperato di ripagare, almeno in parte, gli enormi investimenti fatti al buio nell’intelligenza artificiale. Il mercato non ripaga: le grasse commesse pubbliche, meglio se militari, sì. Con esiti fatali, come dimostra il bombardamento della scuola Minab, in Iran, a fine febbraio
“È la generazione, attraverso modelli, di un reale privo di origine o di realtà: un iper reale. Il territorio non precede più la mappa, né le sopravvive. È tuttavia la mappa che precede il territorio -la precessione dei simulacri- a generare il territorio”, Jean Baudrillard, “Simulacres et Simulation”, 1981.
[...]
Dopo lo sversamento all’esterno dei laboratori di ricerca dei modelli linguistici seguito al lancio di ChatGPT, informatica e politica sembrano preda di un pensiero molto simile a quello dei cartografi del racconto di Borges. La sana fiducia nell’utilità di modelli matematici per predire il comportamento del mondo fisico si è tramutata in fede cieca e assoluta. Secondo le imprese della Silicon Valley (e i loro protettori alla Casa Bianca) dovremmo prendere questi modelli a nostra “mappa del mondo”, per orientarci nel prendere decisioni importanti, soprattutto in emergenza.
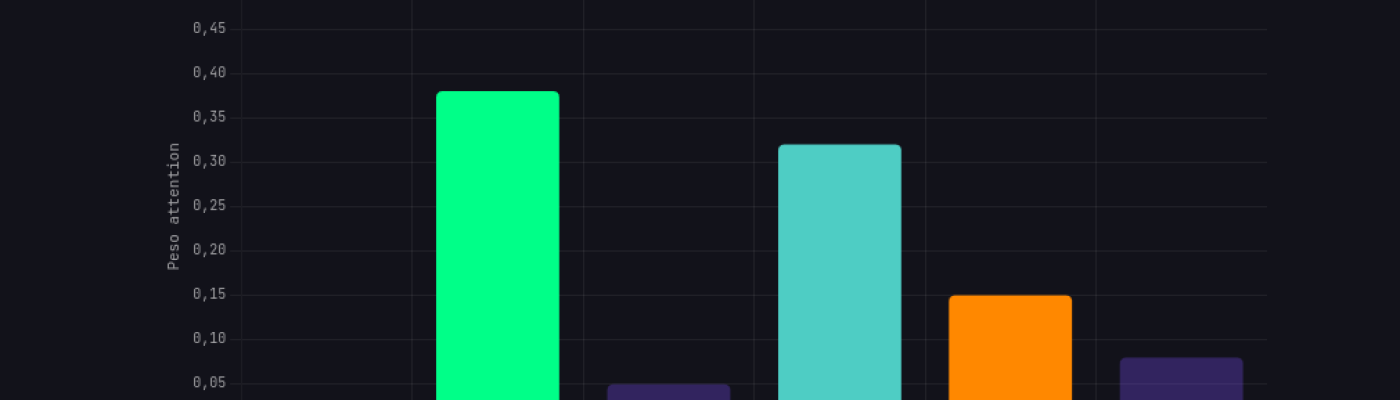
Un LLM smontato pezzo per pezzo. Tokenizzazione, embeddings, attention, hallucinations. Ollama in locale, zero fuffa.
la maggior parte degli articoli che descrivono il funzionamento degli LLM (large Language Model) sono poco attendibili. "L'AI capisce il contesto." "I neuroni si attivano come nel cervello." "Il modello ragiona." Metafore colorate, infografiche carine con le frecce, zero formule, zero codice, zero esperimenti. Gente che spiega cose che non capisce, usando parole che non significano quello che pensano. Una catena di pappagalli che scrivono articoli sui pappagalli.
Allora lo ha scritto Andrea Amani aka The Pirate un articolo che spiega gli LLM.
Ha smontato la macchina pezzo per pezzo.
"Ho Ollama sul Mac con una decina di modelli. Scelgo il più piccolo: llama3.1:8b, 8 miliardi di parametri, 4.9 gigabyte su disco. Il più facile da maneggiare senza sbatti, e tanto l'architettura è identica per tutti: che siano 8 miliardi o 405 miliardi, il meccanismo è lo stesso. Cambiano le dimensioni delle matrici, non come funziona la macchina. Lo apro dal terminale, guardo i byte, e seguo il percorso completo: dal testo che entra al testo che esce. Ogni passaggio, ogni formula, ogni decisione matematica. Niente metafore del cervello. Niente fuffa. Se vuoi capire come funziona una cosa, la smonti. Non leggi chi ne scrive. "

La puntata affronta due argomenti principali: come gli LLM rappresentano una nuova minaccia per la privacy online e l'articolo di Matthew Honnibal che sostiene che i migioramenti dei grandi modelli linguistici non derivini solo da modelli sempre più grandi e costosi.
Il paper “Automated Profile Inference with Language Model Agents” (arXiv:2505.12402) studia una nuova minaccia per la privacy online resa possibile dai modelli linguistici di grandi dimensioni (LLM). Questa minaccia, chiamata inferenza automatizzata del profilo, consiste nell’uso di agenti AI per raccogliere e analizzare automaticamente le attività pubbliche degli utenti su piattaforme pseudonime (come forum o social media) al fine di estrarre informazioni personali sensibili, con il rischio di re-identificare le persone. Why I don’t think AI is a bubble
https://honnibal.dev/blog/ai-bubble
L’autore, sostiene che, al di là delle valutazioni finanziarie, i progressi tecnici dell’IA non mostrano segni di imminente plateau. Contesta l’argomento comune secondo cui i miglioramenti derivino solo dallo “scaling” (modelli sempre più grandi e costosi) e siano quindi destinati a esaurirsi. Honnibal spiega che questa visione, forse valida per i primi modelli come GPT-1 e GPT-2 (definibili “fancy autocomplete”), è oggi superata. Il vero salto di qualità è arrivato dall’integrazione con il reinforcement learning, che ha permesso di creare i cosiddetti “reasoning models”.
I servizi basati su grandi modelli linguistici stanno già avendo impatti sociali enormi, a partire da come vengono prodotti i Grandi Modelli Linguistici (LLM) fino a quali competenze riescono a ottimizzare e sottrarre alle persone. Mentre gli ottimisti si limitano a chiosare che «occorre però adottare un approccio critico», questa tecnica industriale viene promossa a tecnica didattica e inserita nella scuola come uno strumento neutro, la cui adozione obbligatoria è giustificata dal riferimento a valori astratti come creatività e innovazione, e più concretamente ottimizzazione. Non è necessario; ma se si vuole decidere di usarli, una possibile strada alternativa passa per la costruzione di ambienti trasparenti e controllati da chi apprende.
Sommario: Introduzione – Tecniche e ottimizzazione – Tecniche d’importazione – Estrazione e trasformazione di risorse – Una tecnologia opaca – Ambienti aperti e trasparenti.

Nella puntata di domenenica 17 novembre intervistiamo Antonio Casilli sul lavoro nascosto e senza diritti che fa funzionare l'Intelligenza Artificiale; di questi temi parleremo meglio Giovedì 20 al Forte Prenestino con la proiezione di In the belly of AI. Segnaliamo alcune iniziative, poi le notiziole: l'Unione Europea attacca il GDPR per favorire le grandi imprese dell'IA; Google censura video che documentano il genocidio in Palestina: quali alternative?
Nella lunga intervista con Antonio Casilli, professore ordinario all'Istituto Politecnico di Parigi e cofondatore del DiPLab, abbiamo parlato del rapporto tra Intelligenza Artificiale e lavoro: la quantità di lavoro diminuisce a causa dell'intelligenza artificiale? quali sono i nuovi lavori che crea? come si situano nella società le data workers, ovvero le persone che fanno questi lavori? come è strutturata la divisione (internazionale) del lavoro che fa funzionare l'intelligenza artificiale? è vero che sostituisce il lavoro umano?
Per approfondire questi sono alcuni siti di lavoratori che si organizzano menzionati durante la trasmissione:
- https://data-workers.org/
- https://datalabelers.org/
- https://turkopticon.net/
- https://www.alphabetworkersunion.org/
Inoltre:
- L'approfondimento di Entropia Massima, sempre con Antonio Casilli
- L'approfondimento di StakkaStakka di Luglio 2024, sempre con Antonio Casilli
Tra le iniziative:
- lo Scanlendario 2026 a sostegno di Gazaweb
- 27 Novembre, alle cagne sciolte, presentazione del libro "Server donne" di Marzia Vaccari (Agenzia X, 2025)
Ascolta la puntata intera o l'audio dei singoli temi trattati sul sito di Radio Onda Rossa

Le allucinazioni nei modelli linguistici sono un problema intrinseco, non un difetto risolvibile. I tentativi di controllo qualità sui dati richiedono risorse impossibili da ottenere. L’unica soluzione pratica: assistenti personali addestrati su dati limitati
I modelli linguistici rappresentano oggi il cuore pulsante – e più fragile – dell’industria dell’intelligenza artificiale. Tra promesse di precisione e realtà di caos statistico, si rivelano strumenti tanto affascinanti quanto pericolosi, specchio fedele delle illusioni tecnologiche del nostro tempo.
L‘insistenza criminale sui sistemi predittivi fallimentari
C’è solo una cosa peggiore della continua serie di disastri inanellata da tutti i sistemi predittivi nelle pubbliche amministrazioni negli ultimi dieci anni, ed è la criminale, idiota insistenza a volersene dotare.
Uno vorrebbe parlare di informatica parlando di scienza, bene, allora parliamo di tre articoli che i ricercatori in intelligenza artificiale hanno tirato fuori di recente. Ma non temete, non ci mettiamo a discuterli in dettaglio, facciamo un discorso più generale.
leggi l'articolo di Vannini oppure ascolta il suo podcast (Dataknightmare)

Seconda parte del bignamino di Quatrociocchi sugli LLM spiegati senza supercazzole.
Un LLM non è un pensatore profondo: è un sistema statistico addestrato su enormi quantità di testo per modellare le regolarità del linguaggio, senza accesso diretto al mondo reale. Tutto quello che fa è empiricamente descrivibile e riproducibile: nessuna magia, nessun “spirito” emergente.
Riporto di seguito i concetti. L'originale si può leggere su Linkedin

Apple pubblica uno studio che smaschera i limiti dell’intelligenza artificiale: i modelli di AI non “pensano”, ma collassano di fronte a problemi complessi. La corsa verso la vera AGI sembra più lontana che mai.
Negli ultimi giorni, Apple ha scosso il mondo della tecnologia con la pubblicazione di un whitepaper che mette in discussione le fondamenta stesse dell’intelligenza artificiale moderna. Il documento, dal titolo provocatorio “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity” ossia ''L’illusione del pensiero: comprendere i punti di forza e i limiti dei modelli di ragionamento attraverso la lente della complessità dei problemi'', rappresenta una vera e propria bomba sganciata sul settore AI. Dietro la facciata: l’AI non ragiona, imita
Il cuore della ricerca è semplice ma devastante: i Large Language Model (LLM), quei sistemi che oggi chiamiamo “AI” e che aziende come OpenAI, Google e Meta sbandierano come capaci di “pensare”, in realtà non ragionano affatto. Sono semplicemente eccezionali nel riconoscere pattern e riprodurre risposte plausibili, ma quando si tratta di affrontare problemi complessi, la loro presunta intelligenza si sbriciola.

Puntata monografica quella del 2 aprile, in cui abbiamo intervistato Giorgia, una ricercatrice in linguistica riguardo alla definizione, applicazione e limiti dei modelli linguistici nell’ambito dell’intelligenza artificiale.
- Come definiamo una lingua,
- Cosa vuol dire un modello linguistico,
- Come avviene la costruzione di questi mitici modelli linguistici,
- Come definiamo l'addestramento su una lingua.
- E' ancora valida la definizione di pappagalli stocastici per gli LLM (Large Language Model)?
- Cosa è cambiato negli ultimi anni?
Ascolta il podcast della trasmissione sul sito di Radio Blackout
