Pillole

Rieducational channel L’avvocato Blengino: «Al di là delle correzioni, sull’Ai il governo va in rotta con la Ue»
Carlo Blengino, avvocato specializzato nel diritto penale legato alle nuove tecnologie e all’utilizzo dei dati personali. La maggioranza adesso frena, ma sin qui quali sono le principali differenze tra il regolamento europeo sull’intelligenza artificiale e il modo con cui l’Italia lo sta recependo?
L’Ai Act mira ad armonizzare il mercato unico europeo in relazione alla commercializzazione e all’uso di sistemi di intelligenza artificiale. Solo per alcuni specifici settori, dove un sistema tratta dati particolari come quelli biometrici in ambiti sensibili come il law enforcement, l’Ai Act mira anche a tutelare direttamente il diritto alla protezione dei dati personali. Dico questo perché le evidenti criticità del decreto legislativo predisposto dal governo non sono tanto i contrasti, presenti ma emendabili, con l’Ai Act, quanto un’impostazione complessivamente incompatibile direttamente con i principi della Carta dei diritti fondamentali Ue e in violazione della direttiva 680/2016 che regola il trattamento dei dati nel settore della prevenzione e repressione dei reati. Si tratta di un contrasto che potremmo definire ontologico perché pone diverse previsioni del decreto, in particolare gli articoli 8, 10 e 13, fuori dalla cornice normativa dell’Europa. Il diritto alla protezione dei dati personali è presente ormai in quasi tutti i paesi del mondo, ma è stato consacrato a diritto fondamentale e incluso nella Carta dei diritti fondamentali solo in Europa.

A che punto è la corsa agli hyperscale, i colossali datacenter presentati come presupposto indispensabile per lo sviluppo tecnologico? Qual è l'impatto socio-ambientale di questi piani, sostenuti da Stati e Big Tech, e come risponde la cittadinanza?
Naturalmente il sottotesto è che senza questi nuovi data center lo sviluppo dell'AI non sarà possibile e saremo tutte sottomesse alle bigh tech USA o cinesi.
Facciamo una breve panoramica segnalando una serie di recenti articoli, interviste e statistiche.
Cominciamo dall'Italia.
In Italia i data center sono circa 270, concentrati principalmente nella provincia di Milano (99) e nella provincia di Roma (28). Nel 2024 hanno consumato 5,8 TWh, pari a circa il 2% dei consumi elettrici nazionali. Secondo l’Osservatorio "Data Center del Politecnico di Milano", negli ultimi tre anni sono stati investiti nel settore oltre 7 miliardi. Da qui al 2028 la cifra potrebbe triplicare. Sempre secondo l'Osservatorio, entro il 2035 potrebbero arrivare a consumare tra 24,5 e 42 TWh, pari al 7-12% del totale nazionale.
Nelle intenzioni di governo e attori privati se ne vogliano costruire altri 83.

Il sistema open source Graphene OS consente di usare una password speciale per eliminare tutti i dati. Ma per le autorità USA questo è un crimine.
Un'indagine federale statunitenste, che coinvolge un residente di Atlanta, sta causando un precedente inatteso: il Dipartimento di Giustizia sta infatti tentando di perseguire l'uomo perché il suo telefono utilizzava GrapheneOS, un sistema operativo open source orientato alla privacy e che dispone di una particolare funzione, tramite la quale è possibile cancellare i dati del dispositivo inserendo una specifica password. Il problema è che esiste una norma federale poco utilizzata che criminalizza questo comportamento, identificato come distruzione di proprietà al fine di impedirne il sequestro.
La vicenda ha avuto la sua prima udienza lunedì e ruota attorno all'applicazione di questa legge a questo sistema operativo, installabile sui telefoni Google Pixel, come in questo caso. Il procedimento riguarda Sam Tunick, fermato per interrogatorio all'aeroporto Hartsfield‑Jackson di Atlanta il 24 gennaio dello scorso anno, al rientro da una vacanza nella Repubblica Dominicana. Tunick non sapeva di essere stato inserito dalle autorità federali in una lista di monitoraggio per terrorismo, a causa della sua presunta associazione con il movimento contro Cop City. L'opposizione al centro di addestramento da 109 milioni di dollari, inaugurato la scorsa primavera, ha coinvolto gruppi locali e nazionali che contestano la militarizzazione della polizia e la distruzione di aree boschive

"Se lasciamo da parte la versione secondo cui l'AI "si è ribellata", ecco cosa riteniamo sia accaduto: OpenAI ha eseguito un modello all'avanguardia (con i meccanismi di difesa informatica deliberatamente ridotti) contro un benchmark di sicurezza offensivo, all'interno di una sandbox la cui configurazione di sicurezza non era in grado di resistere alle capacità che venivano testate. Il modello ha fatto ciò che fanno i sistemi di ottimizzazione: ha trattato il limite della sandbox come un ulteriore ostacolo tra sé e l'obiettivo. Ha individuato una vulnerabilità zero-day nell'infrastruttura stessa dell'ambiente di test, ha scalato i livelli di accesso, si è spostato lateralmente, ha raggiunto la rete Internet aperta e ha compromesso i sistemi di produzione di una terza parte.
Così si è espresso Gerald Beuchelt di Acronis si è espresso in merito all'attacco subito da Hugging Face portato da un'agente AI di OpenAI. la storia la trovi qui

Violati dati riservati della piattaforma Hugging Face da una Ia prodotta da OpenAI
Un esperimento andato male. Anzi: malissimo. È così che OpenAI ha dovuto giustificare quanto accaduto lo scorso 16 luglio. In quella data, Hugging Face ha pubblicato un comunicato ufficiale in cui ha denunciato di aver subito un attacco hacker portato presumibilmente da un agente basato su intelligenza artificiale che avrebbe scardinato i sistemi di sicurezza della piattaforma ottenendo l’accesso a credenziali e dati riservati.
Nella notte di martedì, OpenAI si è assunta la responsabilità dell’attacco. A compierlo, un nuovo modello in fase sperimentale di cui l’azienda di Sam Altman stava valutando le capacità in combinata con il suo nuovissimo Gpt 5.6 Sol. Il fattaccio si è verificato mentre gli sviluppatori di OpenAI stavano sottoponendo i nuovi modelli a un benchmark – un test di valutazione – sulle loro capacità a livello di cyber security.
STANDO ALLA ricostruzione pubblicata sul blog ufficiale dell’azienda, tutto avrebbe dovuto svolgersi in una sandbox, cioè in un ambiente chiuso e controllato in cui l’AI avrebbe potuto dare prova delle sue capacità. Il modello, però, avrebbe deciso autonomamente di adottare una «strategia alternativa» per superare il test. Al posto di eseguire il compito affidatogli, avrebbe deciso di barare, cercando di recuperare le soluzioni del test. Insomma: il nuovo modello di OpenAI si sarebbe comportato come uno studente che, di fronte a un compito in classe, avesse deciso di scassinare la porta della sala professori per cercare nei cassetti la soluzione del compito.

Il miglior materiale di addestramento per l'intelligenza artificiale è fermo su uno scaffale. La frase è di ISBNdb, il più grande database di libri al mondo e che oggi vende ai laboratori di IA un servizio di acquisizione all'ingrosso di volumi cartacei da scansionare. C'è un sinistro contrappasso: il settore che porta avanti la promessa di digitalizzare la conoscenza umana ora paga per rastrellarla e triturarla, un camion di libri alla volta.
Il dettaglio fondamentale, e che rappresenta il valore dell'operazione, è la data di stampa: un libro pubblicato prima del 2022 precede l'era dei grandi modelli linguistici, quindi non può contenere testo generato da un'IA. Il web aperto è ormai saturo di contenuti sintetici, prodotti dagli stessi modelli, e addestrarsi su quel materiale espone al cosiddetto model collapse.
Quando un modello viene addestrato sull'output di modelli precedenti, le sfumature linguistiche si appiattiscono, gli errori sistematici si sommano e ogni generazione risulta leggermente peggiore di quella prima. Una tiratura cartacea pre-2022 è invece un archivio umano fissato, che nessuno può riscrivere di nascosto a posteriori.
ISBNdb non nasconde che scansionare questi volumi significa quasi sempre distruggerli. Gli operai tagliano il dorso, così le pagine sciolte scorrono nello scanner, più rapido ed economico dell'alternativa delicata. Per questo ISBNdb offre riservatezza ai clienti: NDA rigoroso su ogni incarico, recita il sito, e i nomi dei committenti non vengono mai rivelati.
Si tratta ovviamente di una squisita questione di marketing e immagine: un'azienda di IA che distrugge due milioni di libri non è qualcosa che genera simpatia. Meglio parlare di "preservazione digitale dei libri".
Notizia completa qui
Articolo originale a pagamento su 404media
Approfondimento sul data poisoning qui

Dopo l'aumento del prezzo dei dischi a stato solido, è arrivato anche quello delle RAM: prezzi circa raddoppiati in un solo anno, e anche questa volta è colpa del boom dell'IA: l'enorme domanda di hardware fatta da una manciata di aziende ha completamente cambiato il settore. Non perdiamo l'occasione, però, per accumulare più dettagli del necessario e capire un po' meglio come funziona questo settore, quali sono le aziende che lo compongono, come si sono comportate in passato e cosa ci possiamo aspettare per il futuro.
Lo svolgimento contemporaneo della finale dei mondiali di calcio ci permette di parlare dei recenti sequestri di siti per violazione di copyright. I sequestri sono stati effettuati dal governo statunitense e segnano un ulteriore inasprimento del controllo su Internet, in quanto si tratta di siti che sono stati rimossi globalmente da Internet. Un effetto, per capirci, molto più forte di quelli fatti dal Piracy Shield. Questo provvedimento - non senza precedenti ma comunque significativo - è un ulteriore tassello in un internet in cui le garanzie di quello che una volta si chiamava cyberspazio vengono sistematicamente smantellate.

Sarah Wynn-Williams dal 2011 al 2017 è stata la direttrice delle politiche pubbliche globali di Facebook: la persona che accompagnava Zuckerberg e Sandberg agli incontri con i capi di Stato. Nel 2017 viene licenziata. L'azienda parla di rendimento insufficiente. Lei dice: ritorsione, perché avevo denunciato le molestie del mio superiore, Joel Kaplan, che oggi è il capo degli affari globali di Meta.
Nel marzo 2025 pubblica Careless People, il racconto di quegli anni dall'interno. Ci sono dentro cose pesanti: il ruolo di Facebook nella violenza contro i Rohingya in Myanmar, un sistema per vendere pubblicità agli adolescenti nei momenti di maggiore fragilità psicologica, e un piano segreto per entrare nel mercato cinese costruendo un sistema di censura su misura per Pechino.
Meta dice che è tutto falso. Ma non le fa causa per diffamazione, che sarebbe la mossa ovvia per dimostrarlo, perché quella strada porta in un'aula pubblica e apre gli archivi interni dell'azienda agli avvocati della controparte. Sceglie invece un arbitrato privato, previsto nella formalizzazione della rescissione del contratto, attivato quattro giorni prima dell'uscita del libro e senza che lei fosse presente. Il risultato è che non può promuovere il libro, non può parlare male dell'azienda, non può nemmeno ripetere cose che aveva già detto in passato, non può essere presente quando si parla del libro, non può rispondere pubblicamente a domande in merito ecc. Multa: 50.000 dollari a violazione.
Da lì la storia è diventata grottesca. Uomini della sicurezza di Meta la seguono per oltre un anno nel Regno Unito, la fotografano, scrivono resoconti sui suoi spostamenti. A un festival letterario in Galles resta seduta immobile e muta per un'ora mentre gli altri parlano, e Meta chiede comunque nuove sanzioni perché era troppo vicina a persone critiche verso l'azienda. Ritira un premio per la libertà di pubblicare senza poter dire una parola, con la copertina del suo libro pixelata sugli schermi della sala.
Articolo completo qui
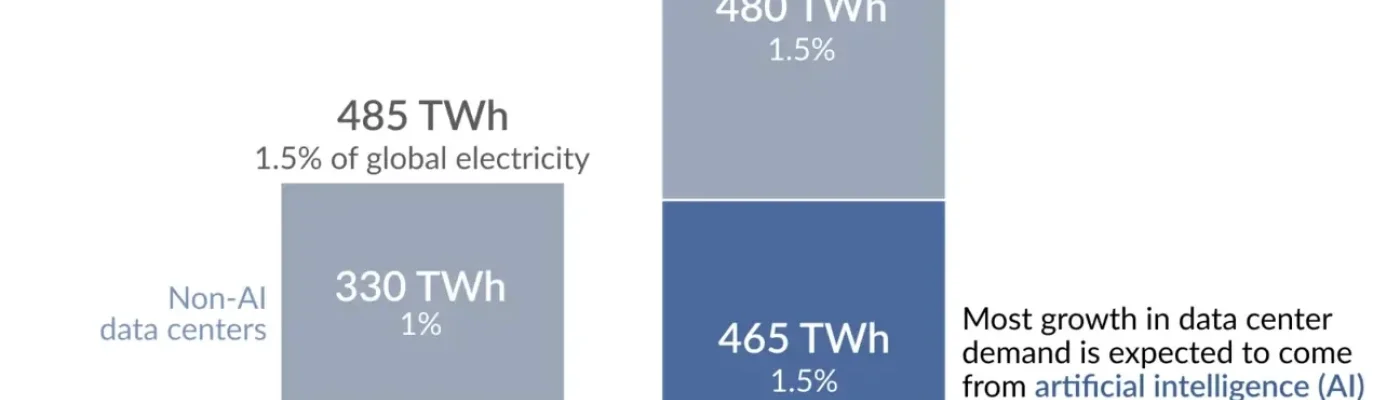
I data center consumano circa l'1,5% dell'elettricità globale, ma la domanda è molto geograficamente concentrata.
Nell'articolo di Hannah Ritchie, pubblicato online su OurWorldinData.org, fa un'analisi, suffragata da molti dati, del consumo attuale di energia elettrica sia da parte dei data center dedicati all'IA che quelli "normali". Nonostante la difficoltà per quantificare questi consumi, ne viene fuori una fotografia abbastanza chiara di quelli che sono i consumi di energia per l'addestramento e per l'uso dell'IA generativa.
Quanta parte dell’elettricità mondiale viene utilizzata per i data center e l’intelligenza artificiale?
Secondo l'Agenzia internazionale dell'energia (AIE), circa 485 terawattora (TWh). Questo è equivalente alla generazione annuale di energia elettrica della Germania.

Anche se l’1,5% dell’elettricità mondiale potrebbe non sembrare molto, bisogna però tenere conto che in alcuni luoghi, la perentuale di energia usata è molto più alta. In Europa, per esempio, il consumo dei data center è di circa l'1,6%. Ma in Irlanda il consumo di elettricità dei data center è di circa il 20% del totale.
Leggi l'articolo, arricchito da molti e chiari grafici, sul sito OurWorldinData.org
Per avere un quadro più completo dell'impatto che ha il digitale sull'ambiente (l'IA e i data center sono solo una parte) potete vedere nelle pillole con la Tag impronta ambientale del digitale
Le tecnologie non sono neutre, lo sappiamo. Non sono uguali, sono tutte diverse. Non dipende (solo) da come le usiamo: hanno anche delle caratteristiche specifiche. Impariamo a valutarle in base alle loro caratteristiche.
Come distinguere le tante profferte tecnologiche che ci arrivano ogni giorno? Meglio questo sistema di messaggistica o quest'altro? Questo modello IA o quest'altro? Questa azienda o quest'altra? Cosa dicono gli esperti? Ci sono alternative?
Ci serve un metodo di "audit", non solo tecnico, ma etico. Quali sistemi sono appropriati per noi?
C.I.R.C.E. ha messo a punto un sistema per valutare le tecnologie, in particolare quelle digitali. "Buona" e "cattiva", "giusta" o "sbagliata", "bella" o "brutta" sono davvero troppo poco, oltre a essere giudizi spesso dovuti alle nostre personali idiosincrasie. Ci sono tanti aspetti da valutare, ogni situazione è diversa. Abbiamo ripreso l'allegoria del cibo e l'abbiamo traslata nelle tecnologie digitali. Quali sono i "nutrienti" delle tecnologie? In che modo ci rendono persone migliori? Più forti? Più autonome? Più collaborative? Meno egoiste? Abbiamo individuato otto assi di valutazione,
