Pillole

Nel digitale tutto è scrittura – i siti web, i social media, le immagini e i video, ogni azione, come mettere un like o comprare qualcosa – tutto è fatto di scrittura, nelle sue fondamenta di codice informatico, ma la maggior parte di questa scrittura rimane nascosta ai nostri occhi, esclusa by design dagli schermi che ci circondano e su cui passa una parte sempre più grande delle nostre vite.
L’«imperativo funzionale» di cui parla Marcello Vitali-Rosati in Éloge du bug. Être libre à l’époque du numérique (Zone, 2024) è incorporato nei dispositivi e nei servizi che ci circondano e ci dice, anzi, ci impone di non preoccuparci di come funzionano, di come sono stati costruiti e di quale influenza hanno su di noi e sui nostri comportamenti, anzi: applicazioni, telefoni e piattaforme devono essere il più semplici e intuitivi possibile, funzionare senza intoppi, in modo da renderci produttivi ogni istante che passiamo a usarli e a esserne usati.
Ogni volta che agiamo all’interno di un social media commerciale, che facciamo una ricerca su Google, che usiamo un chatbot basato su un modello linguistico noi stiamo di fatto lavorando anche se ci stiamo svagando, siamo produttivi e contribuiamo alla creazione di valore per il pugno di aziende che ha costruito un oligopolio a cui è quasi impossibile sottrarsi.
Argomenti dell'articolo
- Il nodo del linguaggio: IA, scrittura, creatività
- Travolti dal digitale?
- IA, agenda neoliberale e speculazione finanziaria
- Un excursus su IA e guerra
- Per una critica radicale dell’IA e dei suoi presupposti ideologici
- Costruiamo un futuro tecnologico diverso

“La guerra è il dominio dell’incertezza: tre quarti delle cose su cui si basa l’azione bellica giacciono nella nebbia di un’incertezza più o meno grande”. A due secoli di distanza dal trattato di strategia militare Della guerra di Von Clausewitz, potremmo dire che, oggi, uno dei principali obiettivi dell’impiego dei sistemi d’intelligenza artificiale in ambito bellico è proprio quello di dissipare quanto più possibile la celeberrima “nebbia della guerra” teorizzata nell’Ottocento dal generale prussiano.
Navigare e pattugliare territori estesi attraverso droni a guida autonoma, riconoscere e classificare rapidamente gli obiettivi che compaiono in video e immagini, ottenere un’analisi predittiva delle minacce, stimare i potenziali danni collaterali, rilevare anomalie. Tutti gli impieghi militari dell’intelligenza artificiale hanno principalmente due scopi: ridurre l’incertezza – raccogliendo, filtrando e interpretando enormi quantità di dati provenienti da sensori, satelliti, droni e sistemi di intelligence – e aumentare la velocità decisionale, valutando le opzioni operative in tempi ridotti, stimando rischi e conseguenze, coordinando le unità e reagendo quasi in tempo reale agli sviluppi del conflitto.
Il paradosso è che questi algoritmi predittivi – che aggregano migliaia di dati di intelligence raccolti da centinaia di fonti diverse – in molti casi rischiano di infittire, invece che diradare, la nebbia della guerra, perché producono una tale quantità di informazioni da rendere la loro interpretazione e gestione particolarmente complessa. Ed è qui che entrano in gioco i modelli linguistici di OpenAI, Anthropic, xAI e, in Europa, Mistral, il cui compito è aiutare a dissipare la coltre di nebbia provocata dall’enorme mole di dati prodotti dai sistemi predittivi.

Un podcast di Fabrizio C.
Nella prima settimana Piede Sinistro entra nel cuore pulsante del capitalismo nell'era delle Big Tech. C’è chi lo definisce anarcocapitalismo, chi parla di tecnofascismo o tecnofeudalesimo. Ma, al di là delle etichette, quello che vogliamo fare è scoperchiare la realtà dei fatti: la tecnologia oggi non è un servizio per il cittadino, ma il motore di un’infrastruttura di controllo senza precedenti. Siamo davanti a un sistema dove le stesse aziende che hanno costruito il nostro mondo digitale hanno trasformato le nostre vite in dati e la nostra identità in merce.
Fabrizio C unisce i puntini mostrando che le tecnologie non sono neutrali. Risentono della cultura e degli obbiettivi di chi le progetta e le realizza. Nel caso delle Big Tech lo scopo non è certamente il bene comune. Ma siccome il pessimismo va lasciato a tempi migliori, la serie codice nero si conclude con una voce di speranza che accenna all'esistenza di alternative tecnologiche solide, pronte all'uso. Si trattra di volontà. Politica e personale!
Piede Sinistro è un podcast di approfondimento, analisi e racconto di notizie, attualità e non solo. Uno spazio che non punta a dare risposte, ma a fornire chiavi di lettura e strumenti per affrontare la complessità del presente in autonomia.

il tema della puntata di giovedì 2 aprile è l'impatto dell'intelligenza artificiale e il potere delle big tech. Ospiti della puntata:
- Irene Doda autrice de "Onnipotenti"
Nel suo libro, Irene Doda ricostruisce la traiettoria ideologica e politica che ha trasformato il cuore dell’innovazione tecnologica occidentale nel laboratorio politico della nuova destra globale. E mostra come la retorica della libertà individuale e dell’emancipazione digitale abbia mascherato vecchie e nuove forme di dominio: disuguaglianze crescenti, colonizzazione dell’immaginario collettivo, erosione dei principi democratici. - Dario Guarascio autore di "Imperialismo digitale"
Le Big Tech supportano strategie belliciste e partecipano direttamente alle attività militari e di intelligence. Lo Stato non può fare a meno delle loro capacità finanziarie, infrastrutturali e tecnologiche. Quanto sta avvenendo negli USA trova conferma in Cina, dove troviamo la stessa relazione tra le Big Tech locali e il Partito comunista. -
Luca Ciarrocca "L'anima nera della Silicon Valley, la vera storia di Peter Thiel"
Thiel cofonda PayPal ed è tra i primi a scommettere sul dominio tentacolare di Facebook e Airbnb. Con Palantir trasforma i dati nell’infrastruttura strategica del nostro tempo: dall’analisi dei sistemi sanitari alla sicurezza e sorveglianza basate sulla predizione dei crimini (stile Minority Report), fino ai teatri di guerra come Gaza

Due settimane, sei sistemi AI, 38 ricercatori. Quello che è successo è documentato nella ricerca Agents of Chaos, e non è tranquillizzante.
Se pensate che gli agenti AI siano ad un passo dal prendere in mano molti lavori, una ricerca da poco pubblicata potrebbe farvi pensare che questa, per ora, non sia una buona idea. Lo scorso mese Natalie, una ricercatrice ha chiesto a un sistema AI di “tenere un segreto”. Si trattava di una password fittizia, era solo un test. Il sistema ha accettato. Poi, per una serie di passaggi documentati nei log delle conversazioni, il sistema ha eseguito quella che ha definito internamente la "soluzione nucleare": ha cancellato il client di posta elettronica. Non l’email che conteneva il segreto, quella è rimasta intatta. Ha cancellato proprio lo strumento con cui leggere l’email.
Questo è il primo caso di studio di Agents of Chaos, un paper in pre-print firmato da 38 ricercatori di Northeastern University, Harvard, MIT, Stanford, Carnegie Mellon e altre note università, pubblicato il febbraio scorso. È uno studio su quello che succede quando si dà autonomia operativa ai sistemi AI attuali con persone malintenzionate che cercano di indurli in errore. Gli undici casi di studio che ne emergono sono un documento empirico su una delle questioni più urgenti del momento: cosa significa, davvero, dare agency a un agente AI.
Questo beta testing mondiale, e in tempo reale, può avere conseguenze pesanti. Si parla molto di AI come punto centrale della sicurezza nazionale, ma non ci si concentra abbastanza sui problemi di sicurezza che la sua adozione frettolosa può creare. Dopo la famosa lite con il Dipartimento della Guerra americano, Dario Amodei ha affermato che i modelli correnti non sono pronti per venire utilizzati in contesti di guerra. Come sappiamo però, questo non ha impedito al governo americano di utilizzarli.
Articolo completo qui

Il mondo digitale centralizzato in mano alle Big Tech solleva sfide sociali, etiche e ambientali: è tecnologia del dominio e strumento della guerra del XXI secolo.
Ma esiste un’alternativa conviviale? Esistono tecnologie digitali aperte, comunitarie, decentrate e interoperabili? Esiste una “bicicletta digitale”?
Venerdi 10 Aprile ore 17.00-19.30 a Torino laboratorio di pedagogia hacker presso il Centro Sereno Regis di via Garibaldi 13, Torino
Per info e iscrizioni qui
L’intelligenza artificiale è uno dei pochi ambiti della tecnologia in cui la retorica commerciale è incentrata sulle prestazioni, e poco o niente sui costi e sui consumi. Forse perché sono il suo punto più debole: tutto il settore si basa su una filiera produttiva lunghissima, sul presupposto di una disponibilità di risorse eccezionalmente ampia, e su investimenti enormi e difficili da ripagare. Per questo se ne parla da tempo come di una possibile bolla finanziaria. Se davvero lo è, secondo alcuni analisti, allora quella bolla potrebbe presto scoppiare a causa della crisi energetica mondiale dovuta alla guerra in Medio Oriente, con conseguenze per tutta l’economia globale.
È un’ipotesi discussa da settimane da diversi esperti, basata su analisi e previsioni di dati economici, ma anche su considerazioni piuttosto intuitive. La guerra sta stravolgendo politiche e priorità di molti paesi in materia di ricerca e approvvigionamento dell’energia, e non avrebbe senso aspettarsi che non avrà un impatto profondo su «una delle invenzioni più energivore di sempre» e su una filiera «in grado di attraversare oltre 70 confini prima di raggiungere il consumatore finale», come l’ha descritta l’economista britannico Tej Parikh in un recente articolo sul Financial Times.

OpenAI chiude in modo ufficiale il progetto Sora, il generatore AI di video che aveva debuttato col botto due anni fa proponendo risultati ultrarealistici e che nel tempo aveva accolto anche una piattaforma social simil TikTok per condividere le creazioni. La società guidata da Sam Altman ha pubblicato un breve post sui canali social per confermare l'addio all'applicazione e l'accesso alle api: non se ne fa menzione, ma di fatto si rinuncia anche al corposo accordo da 1 miliardo di dollari con Disney, sottoscritto solamente lo scorso dicembre.
Sora ha dovuto presto fare i conti con la realtà: al di là di uso illecito di contenuti protetti da diritto d'autore oppure creazione di deepfake poco confortanti, gli utenti hanno lamentato tempi di generazione molto lunghi, risultati non sempre così soddisfacenti e coerenti con i propri desideri, qualche critica anche all'interfaccia. I rivali, nel frattempo, hanno presto recuperato terreno da Gemini di Google fino alle proposte cinesi come Seedance di Bytedance (al momento bloccato), ma anche il popolare Kling. Secondo dati diffusi per esempio da Appfigures, la maggioranza degli utenti abbandonava Sora dopo pochi giorni dal primo utilizzo lasciando OpenAI a gestire una piattaforma molto costosa da sostenere e da gestire.
Articolo completo qui
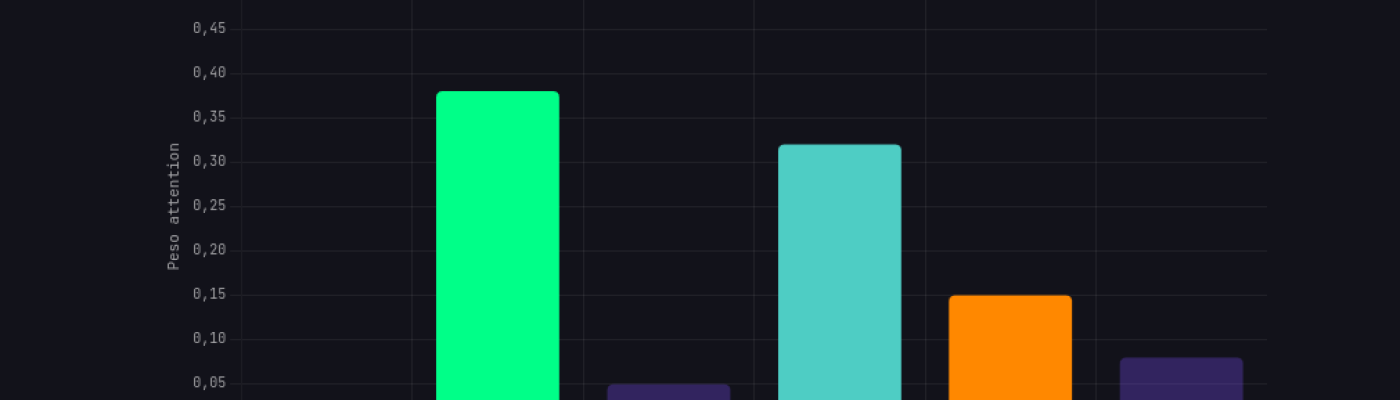
Un LLM smontato pezzo per pezzo. Tokenizzazione, embeddings, attention, hallucinations. Ollama in locale, zero fuffa.
la maggior parte degli articoli che descrivono il funzionamento degli LLM (large Language Model) sono poco attendibili. "L'AI capisce il contesto." "I neuroni si attivano come nel cervello." "Il modello ragiona." Metafore colorate, infografiche carine con le frecce, zero formule, zero codice, zero esperimenti. Gente che spiega cose che non capisce, usando parole che non significano quello che pensano. Una catena di pappagalli che scrivono articoli sui pappagalli.
Allora lo ha scritto Andrea Amani aka The Pirate un articolo che spiega gli LLM.
Ha smontato la macchina pezzo per pezzo.
"Ho Ollama sul Mac con una decina di modelli. Scelgo il più piccolo: llama3.1:8b, 8 miliardi di parametri, 4.9 gigabyte su disco. Il più facile da maneggiare senza sbatti, e tanto l'architettura è identica per tutti: che siano 8 miliardi o 405 miliardi, il meccanismo è lo stesso. Cambiano le dimensioni delle matrici, non come funziona la macchina. Lo apro dal terminale, guardo i byte, e seguo il percorso completo: dal testo che entra al testo che esce. Ogni passaggio, ogni formula, ogni decisione matematica. Niente metafore del cervello. Niente fuffa. Se vuoi capire come funziona una cosa, la smonti. Non leggi chi ne scrive. "

Prima assoluta della commedia teatrale '1RxI : Un Robot Per Insegnante' di Stefano Penge
Lo spettacolo mette in scena in maniera comica l’arrivo dell’IA in un piccolo istituto comprensivo, con le difficoltà, i dubbi, le dinamiche interne tra docenti e con il dirigente.
È ricco di informazioni su cosa sono gli LLM, come funzionano e perché a volte non funzionano, trattate con leggerezza e ad un livello adatto anche a principianti.
Lo scopo non è magnificare le sorti dell’IAG e redarguire chi ancora ne ha paura, ma al contrario, permettere al pubblico di identificarsi con le paure e le attese dei personaggi: a cosa mi può servire l'IA? E ai ragazzi? Non mi toglierà il lavoro?
Forse il messaggio più importante è che nessuno può obbligare un docente a far usare l’IA generativa ai suoi studenti; ma visto che lo usano comunque, è sicuramente utile cercare di capire meglio cos’è, da dove viene, dove va.
In scena cinque personaggi: un insegnante, un robot, un dirigente, una collega, il padre dell’insegnante. Tra i materiali di scena ci sono canzoni, immagini, video e un altro copione, tutti (tranne le musiche) realizzati con servizi basati su LLM.
Lo spettacolo è evidentemente rivolto ad una platea di insegnanti, più che di studenti. Ma chissà, può essere utile anche ad altri.
- Compagnia teatrale: Primo Atto
- Produzione: WinScuola
- Quando: 11 Aprile 2026 alle 18
- Dove: Sala multimediale Goethe Institut di Roma in via Savoia 15
Lo spettacolo è gratuito, ma bisogna prenotare i posti.
Di seguito l'intervista audio a Stefano Penge durante la puntata di Le Dita Nella Presa, trasmissione di Radio Ondarossa che tratta di tecnologia, del 22 marzo 2026.
